![]()
Set-up instructions: this notebook give a tutorial on the forecasting learning task supported by sktime. On binder, this should run out-of-the-box.
To run this notebook as intended, ensure that sktime with basic dependency requirements is installed in your python environment.
To run this notebook with a local development version of sktime, either uncomment and run the below, or pip install -e a local clone of the sktime main branch.
[ ]:
# from os import sys
# sys.path.append("..")
Forecasting with sktime#
In forecasting, past data is used to make temporal forward predictions of a time series. This is notably different from tabular prediction tasks supported by scikit-learn and similar libraries.
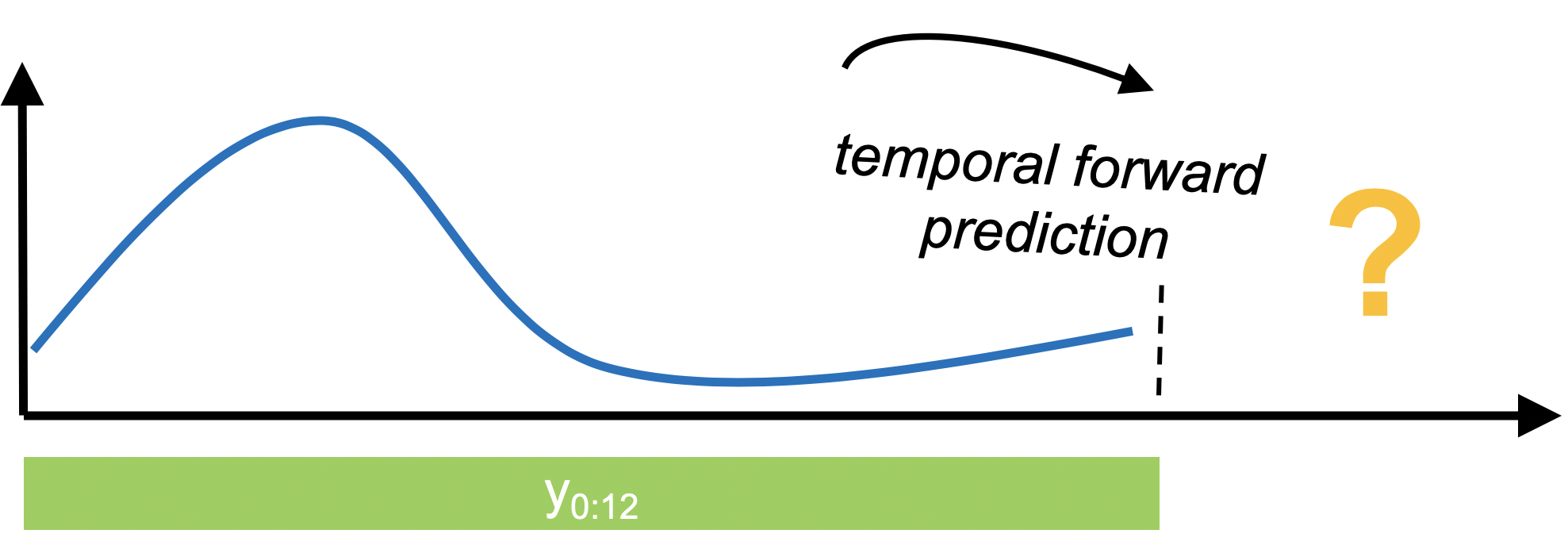
sktime provides a common, scikit-learn-like interface to a variety of classical and ML-style forecasting algorithms, together with tools for building pipelines and composite machine learning models, including temporal tuning schemes, or reductions such as walk-forward application of scikit-learn regressors.
Section 1 provides an overview of common forecasting workflows supported by sktime.
Section 2 discusses the families of forecasters available in sktime.
Section 3 discusses advanced composition patterns, including pipeline building, reduction, tuning, ensembling, and autoML.
Section 4 gives an introduction to how to write custom estimators compliant with the sktime interface.
Further references: * for further details on how forecasting is different from supervised prediction à la scikit-learn, and pitfalls of misdiagnosing forecasting as supervised prediction, have a look at this notebook * for a scientific reference, take a look at our paper on forecasting with sktime in which we discuss sktime’s forecasting module in more detail and use it to replicate and extend the M4 study.
Table of Contents#
1. Basic forecasting workflows
1.2 Basic deployment workflow – batch fitting and forecasting
1.2.2 Forecasters that require the horizon already in “fit` <#section_1_2_2>`__
1.3 basic evaluation workflow – evaluating a batch of forecasts against ground truth observations
1.4 advanced deployment workflow: rolling updates & forecasts
1.5 advanced evaluation worfklow: rolling re-sampling and aggregate errors, rolling back-testing
3. Advanced composition patterns – pipelines, reduction, autoML, and more
package imports#
[ ]:
import numpy as np
import pandas as pd
1. Basic forecasting workflows#
This section explains the basic forecasting workflows, and key interface points for it.
We cover the following four workflows:
basic deployment workflow: batch fitting and forecasting
basic evaluation workflow: evaluating a batch of forecasts against ground truth observations
advanced deployment workflow: fitting and rolling updates/forecasts
advanced evaluation worfklow: using rolling forecast splits and computing split-wise and aggregate errors, including common back-testing schemes
All workflows make common assumptions on the input data format.
sktime uses pandas for representing time series:
pd.Seriesfor univariate time series and sequencespd.DataFramefor multivariate time series and sequences
The Series.index and DataFrame.index are used for representing the time series or sequence index. sktime supports pandas integer, period and timestamp indices.
NOTE: at current time (v0.9x), forecasting of multivariate time series is a stable functionality, but not covered in this tutorial. Contributions to extend the tutorial are welcome.
Example: as the running example in this tutorial, we use a textbook data set, the Box-Jenkins airline data set, which consists of the number of monthly totals of international airline passengers, from 1949 – 1960. Values are in thousands. See “Makridakis, Wheelwright and Hyndman (1998) Forecasting: methods and applications”, exercises sections 2 and 3.
[ ]:
from sktime.datasets import load_airline
from sktime.utils.plotting import plot_series
[ ]:
y = load_airline()
# plotting for visualization
plot_series(y)
[ ]:
y.index
Generally, users are expected to use the in-built loading functionality of pandas and pandas-compatible packages to load data sets for forecasting, such as read_csv or the Series or DataFrame constructors if data is available in another in-memory format, e.g., numpy.array.
sktime forecasters may accept input in pandas-adjacent formats, but will produce outputs in, and attempt to coerce inputs to, pandas formats.
NOTE: if your favourite format is not properly converted or coerced, kindly consider to contribute that functionality to sktime.
The simplest use case workflow is batch fitting and forecasting, i.e., fitting a forecasting model to one batch of past data, then asking for forecasts at time point in the future.
The steps in this workflow are as follows:
preparation of the data
specification of the time points for which forecasts are requested. This uses a
numpy.arrayor theForecastingHorizonobject.specification and instantiation of the forecaster. This follows a
scikit-learn-like syntax; forecaster objects follow the familiarscikit-learnBaseEstimatorinterface.fitting the forecaster to the data, using the forecaster’s
fitmethodmaking a forecast, using the forecaster’s
predictmethod
The below first outlines the vanilla variant of the basic deployment workflow, step-by-step.
At the end, one-cell workflows are provided, with common deviations from the pattern (Sections 1.2.1 and following).
step 1 – preparation of the data#
as discussed in Section 1.1, the data is assumed to be in pd.Series or pd.DataFrame format.
[ ]:
from sktime.datasets import load_airline
from sktime.utils.plotting import plot_series
[ ]:
# in the example, we use the airline data set.
y = load_airline()
plot_series(y)
step 2 – specifying the forecasting horizon#
Now we need to specify the forecasting horizon and pass that to our forecasting algorithm.
There are two main ways:
using a
numpy.arrayof integers. This assumes either integer index or periodic index (PeriodIndex) in the time series; the integer indicates the number of time points or periods ahead we want to make a forecast for. E.g.,1means forecast the next period,2the second next period, and so on.using a
ForecastingHorizonobject. This can be used to define forecast horizons, using any supported index type as an argument. No periodic index is assumed.
Forecasting horizons can be absolute, i.e., referencing specific time points in the future, or relative, i.e., referencing time differences to the present. As a default, the present is that latest time point seen in any y passed to the forecaster.
numpy.array based forecasting horizons are always relative; ForecastingHorizon objects can be both relative and absolute. In particular, absolute forecasting horizons can only be specified using ForecastingHorizon.
using a numpy forecasting horizon#
[ ]:
fh = np.arange(1, 37)
fh
This will ask for monthly predictions for the next three years, since the original series period is 1 month. In another example, to predict only the second and fifth month ahead, one could write:
import numpy as np
fh = np.array([2, 5]) # 2nd and 5th step ahead
Using a ForecastingHorizon based forecasting horizon#
The ForecastingHorizon object takes absolute indices as input, but considers the input absolute or relative depending on the is_relative flag.
ForecastingHorizon will automatically assume a relative horizon if temporal difference types from pandas are passed; if value types from pandas are passed, it will assume an absolute horizon.
To define an absolute ForecastingHorizon in our example:
[ ]:
from sktime.forecasting.base import ForecastingHorizon
[ ]:
fh = ForecastingHorizon(
pd.PeriodIndex(pd.date_range("1961-01", periods=36, freq="M")), is_relative=False
)
fh
ForecastingHorizon-s can be converted from relative to absolute and back via the to_relative and to_absolute methods. Both of these conversions require a compatible cutoff to be passed:
[ ]:
cutoff = pd.Period("1960-12", freq="M")
[ ]:
fh.to_relative(cutoff)
[ ]:
fh.to_absolute(cutoff)
step 3 – specifying the forecasting algorithm#
To make forecasts, a forecasting algorithm needs to be specified. This is done using a scikit-learn-like interface. Most importantly, all sktime forecasters follow the same interface, so the preceding and remaining steps are the same, no matter which forecaster is being chosen.
For this example, we choose the naive forecasting method of predicting the last seen value. More complex specifications are possible, using pipeline and reduction construction syntax; this will be covered later in Section 2.
[ ]:
from sktime.forecasting.naive import NaiveForecaster
[ ]:
forecaster = NaiveForecaster(strategy="last")
step 4 – fitting the forecaster to the seen data#
Now the forecaster needs to be fitted to the seen data:
[ ]:
forecaster.fit(y)
step 5 – requesting forecasts#
Finally, we request forecasts for the specified forecasting horizon. This needs to be done after fitting the forecaster:
[ ]:
y_pred = forecaster.predict(fh)
[ ]:
# plotting predictions and past data
plot_series(y, y_pred, labels=["y", "y_pred"])
1.2.1 the basic deployment workflow in a nutshell#
for convenience, we present the basic deployment workflow in one cell. This uses the same data, but different forecaster: predicting the latest value observed in the same month.
[ ]:
from sktime.datasets import load_airline
from sktime.forecasting.base import ForecastingHorizon
from sktime.forecasting.naive import NaiveForecaster
[ ]:
# step 1: data specification
y = load_airline()
# step 2: specifying forecasting horizon
fh = np.arange(1, 37)
# step 3: specifying the forecasting algorithm
forecaster = NaiveForecaster(strategy="last", sp=12)
# step 4: fitting the forecaster
forecaster.fit(y)
# step 5: querying predictions
y_pred = forecaster.predict(fh)
[ ]:
# optional: plotting predictions and past data
plot_series(y, y_pred, labels=["y", "y_pred"])
1.2.2 forecasters that require the horizon already in fit#
Some forecasters need the forecasting horizon provided already in fit. Such forecasters will produce informative error messages when it is not passed in fit. All forecaster will remember the horizon when already passed in fit for prediction. The modified workflow to allow for such forecasters in addition is as follows:
[ ]:
# step 1: data specification
y = load_airline()
# step 2: specifying forecasting horizon
fh = np.arange(1, 37)
# step 3: specifying the forecasting algorithm
forecaster = NaiveForecaster(strategy="last", sp=12)
# step 4: fitting the forecaster
forecaster.fit(y, fh=fh)
# step 5: querying predictions
y_pred = forecaster.predict()
1.2.3 forecasters that can make use of exogeneous data#
Many forecasters can make use of exogeneous time series, i.e., other time series that are not forecast, but are useful for forecasting y. Exogeneous time series are always passed as an X argument, in fit, predict, and other methods (see below). Exogeneous time series should always be passed as pandas.DataFrames. Most forecasters that can deal with exogeneous time series will assume that the time indices of X passed to fit are a super-set of the time indices in y
passed to fit; and that the time indices of X passed to predict are a super-set of time indices in fh, although this is not a general interface restriction. Forecasters that do not make use of exogeneous time series still accept the argument (and do not use it internally).
The general workflow for passing exogeneous data is as follows:
[ ]:
# step 1: data specification
y = load_airline()
# we create some dummy exogeneous data
X = pd.DataFrame(index=y.index)
# step 2: specifying forecasting horizon
fh = np.arange(1, 37)
# step 3: specifying the forecasting algorithm
forecaster = NaiveForecaster(strategy="last", sp=12)
# step 4: fitting the forecaster
forecaster.fit(y, X=X, fh=fh)
# step 5: querying predictions
y_pred = forecaster.predict(X=X)
NOTE: as in workflows 1.2.1 and 1.2.2, some forecasters that use exogeneous variables may also require the forecasting horizon only in predict. Such forecasters may also be called with steps 4 and 5 being
forecaster.fit(y, X=X)
y_pred = forecaster.predict(fh=fh, X=X)
1.2.4. multivariate forecasting#
Some forecasters in sktime support multivariate forecasts. Some examples of multivariate forecasters are: MultiplexForecaster, EnsembleForecaster,TransformedTargetForecaster etc. In order to determine is a forecaster can be multivariate, one can look at the scitype:y in tags, which should be set to multivariate or ’both.
To display complete list of multivariate forecasters, search for forecasters with ‘multivariate’ or ‘both’ tag value for the tag ‘scitype:y’, as follows:
[ ]:
from sktime.registry import all_estimators
for forecaster in all_estimators(filter_tags={"scitype:y": ["multivariate", "both"]}):
print(forecaster[0])
Below is an example of the general workflow of multivariate ColumnEnsembleForecaster using the longley dataset from sktime.datasets. The workflow is the same as in the univariate forecasters, but the input has more than one variables (columns).
[ ]:
from sktime.datasets import load_longley
from sktime.forecasting.compose import ColumnEnsembleForecaster
from sktime.forecasting.exp_smoothing import ExponentialSmoothing
from sktime.forecasting.trend import PolynomialTrendForecaster
_, y = load_longley()
y = y.drop(columns=["UNEMP", "ARMED", "POP"])
forecasters = [
("trend", PolynomialTrendForecaster(), 0),
("ses", ExponentialSmoothing(trend="add"), 1),
]
forecaster = ColumnEnsembleForecaster(forecasters=forecasters)
forecaster.fit(y, fh=[1, 2, 3])
y_pred = forecaster.predict()
The input to the multivariate forecaster y is a pandas.DataFrame where each column is a variable.
[ ]:
y
The result of the multivariate forecaster y_pred is a pandas.DataFrame where columns are the predicted values for each variable. The variables in y_pred are the same as in y, the input to the multivariate forecaster.
[ ]:
y_pred
1.2.5 probabilistic forecasting: prediction intervals, quantile, variance, and distributional forecasts#
sktime provides a unified interface to make probabilistic forecasts. The following methods are possibly available for probabilistic forecasts:
predict_intervalproduces interval forecasts. Additionally to anypredictarguments, an argumentcoverage(nominal interval coverage) must be provided.predict_quantilesproduces quantile forecasts. Additionally to anypredictarguments, an argumentalpha(quantile values) must be provided.predict_varproduces variance forecasts. This has same arguments aspredict.predict_probaproduces full distributional forecasts. This has same arguments aspredict.
Not all forecasters are capable of returning probabilistic forecast, but if a forecasters provides one kind of probabilistic forecast, it is also capable of returning the others. The list of forecasters with such capability can be queried by registry.all_estimators, searching for those where the capability:pred_int tag has valueTrue.
The basic worfklow for probabilistic forecasts is similar to the basic forecasting workflow, with the difference that instead of predict, one of the probabilistic forecasting methods is used:
[ ]:
import numpy as np
from sktime.datasets import load_airline
from sktime.forecasting.theta import ThetaForecaster
# until fit, identical with the simple workflow
y = load_airline()
fh = np.arange(1, 13)
forecaster = ThetaForecaster(sp=12)
forecaster.fit(y, fh=fh)
Now we present the different probabilistic forecasting methods.
predict_interval – interval predictions#
predict_interval takes an argument coverage, which is a float (or list of floats), the nominal coverage of the prediction interval(s) queried. predict_interval produces symmetric prediction intervals, for example, a coverage of 0.9 returns a “lower” forecast at quantile 0.5 - coverage/2 = 0.05, and an “upper” forecast at quantile 0.5 + coverage/2 = 0.95.
[ ]:
coverage = 0.9
y_pred_ints = forecaster.predict_interval(coverage=coverage)
y_pred_ints
The return y_pred_ints is a pandas.DataFrame with a column multi-index: The first level is variable name from y in fit (or Coverage if no variable names were present), second level coverage fractions for which intervals were computed, in the same order as in input coverage; third level columns lower and upper. Rows are the indices for which forecasts were made (same as in y_pred or fh). Entries are lower/upper (as column name) bound of the nominal coverage
predictive interval for the index in the same row.
pretty-plotting the predictive interval forecasts:
[ ]:
from sktime.utils import plotting
# also requires predictions
y_pred = forecaster.predict()
fig, ax = plotting.plot_series(y, y_pred, labels=["y", "y_pred"])
ax.fill_between(
ax.get_lines()[-1].get_xdata(),
y_pred_ints["Coverage"][coverage]["lower"],
y_pred_ints["Coverage"][coverage]["upper"],
alpha=0.2,
color=ax.get_lines()[-1].get_c(),
label=f"{coverage}% prediction intervals",
)
ax.legend();
predict_quantiles – quantile forecasts#
sktime offers predict_quantiles as a unified interface to return quantile values of predictions. Similar to predict_interval.
predict_quantiles has an argument alpha, containing the quantile values being queried. Similar to the case of the predict_interval, alpha can be a float, or a list of floats.
[ ]:
y_pred_quantiles = forecaster.predict_quantiles(alpha=[0.275, 0.975])
y_pred_quantiles
y_pred_quantiles, the output of predict_quantiles, is a pandas.DataFrame with a two-level column multiindex. The first level is variable name from y in fit (or Quantiles if no variable names were present), second level are the quantile values (from alpha) for which quantile predictions were queried. Rows are the indices for which forecasts were made (same as in y_pred or fh). Entries are the quantile predictions for that variable, that quantile value, for the time
index in the same row.
Remark: for clarity: quantile and (symmetric) interval forecasts can be translated into each other as follows.
alpha < 0.5: The alpha-quantile prediction is equal to the lower bound of a predictive interval with coverage = (0.5 – alpha) * 2
alpha > 0.5: The alpha-quantile prediction is equal to the upper bound of a predictive interval with coverage = (alpha – 0.5) * 2
predict_var – variance predictions#
predict_var produces variance predictions:
[ ]:
y_pred_var = forecaster.predict_var()
y_pred_var
The format of the output y_pred_var is the same as for predict, except that this is always coerced to a pandas.DataFrame, and entries are not point predictions but variance predictions.
predict_proba – distribution predictions#
To predict full predictive distributions, predict_proba can be used. As this returns tensorflow Distribution objects, the deep learning dependency set dl of sktime (which includes tensorflow and tensorflow-probability dependencies) must be installed.
[ ]:
y_pred_proba = forecaster.predict_proba()
y_pred_proba
Distributions returned by predict_proba are by default marginal at time points, not joint over time points. More precisely, the returned Distribution object is formatted and to be interpreted as follows: * batch shape is 1D and same length as fh * event shape is 1D, with length equal to number of variables being forecast * i-th (batch) distribution is forecast for i-th entry of fh * j-th (event) component is j-th variable, same order as y in fit/update
To return joint forecast distributions, the marginal parameter can be set to False (currently work in progress). In this case, a Distribution with 2D event shape (len(fh), len(y)) is returned.
1.3 basic evaluation workflow – evaluating a batch of forecasts against ground truth observations#
It is good practice to evaluate statistical performance of a forecaster before deploying it, and regularly re-evaluate performance if in continuous deployment. The evaluation workflow for the basic batch forecasting task, as solved by the workflow in Section 1.2, consists of comparing batch forecasts with actuals. This is sometimes called (batch-wise) backtesting.
The basic evaluation workflow is as follows:
splitting a representatively chosen historical series into a temporal training and test set. The test set should be temporally in the future of the training set.
obtaining batch forecasts, as in Section 1.2, by fitting a forecaster to the training set, and querying predictions for the test set
specifying a quantitative performance metric to compare the actual test set against predictions
computing the quantitative performance on the test set
testing whether this performance is statistically better than a chosen baseline performance
NOTE: step 5 (testing) is currently not supported in sktime, but is on the development roadmap. For the time being, it is advised to use custom implementations of appropriate methods (e.g., Diebold-Mariano test; stationary confidence intervals).
NOTE: note that this evaluation set-up determines how well a given algorithm would have performed on past data. Results are only insofar representative as future performance can be assumed to mirror past performance. This can be argued under certain assumptions (e.g., stationarity), but will in general be false. Monitoring of forecasting performance is hence advised in case an algorithm is applied multiple times.
Example: In the example, we will us the same airline data as in Section 1.2. But, instead of predicting the next 3 years, we hold out the last 3 years of the airline data (below: y_test), and see how the forecaster would have performed three years ago, when asked to forecast the most recent 3 years (below: y_pred), from the years before (below: y_train). “how” is measured by a quantitative performance metric (below: mean_absolute_percentage_error). This is then considered as
an indication of how well the forecaster would perform in the coming 3 years (what was done in Section 1.2). This may or may not be a stretch depending on statistical assumptions and data properties (caution: it often is a stretch – past performance is in general not indicative of future performance).
step 1 – splitting a historical data set in to a temporal train and test batch#
[ ]:
from sktime.forecasting.model_selection import temporal_train_test_split
[ ]:
y = load_airline()
y_train, y_test = temporal_train_test_split(y, test_size=36)
# we will try to forecast y_test from y_train
[ ]:
# plotting for illustration
plot_series(y_train, y_test, labels=["y_train", "y_test"])
print(y_train.shape[0], y_test.shape[0])
step 2 – making forecasts for y_test from y_train#
This is almost verbatim the workflow in Section 1.2, using y_train to predict the indices of y_test.
[ ]:
# we can simply take the indices from `y_test` where they already are stored
fh = ForecastingHorizon(y_test.index, is_relative=False)
forecaster = NaiveForecaster(strategy="last", sp=12)
forecaster.fit(y_train)
# y_pred will contain the predictions
y_pred = forecaster.predict(fh)
[ ]:
# plotting for illustration
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
steps 3 and 4 – specifying a forecasting metric, evaluating on the test set#
The next step is to specify a forecasting metric. These are functions that return a number when input with prediction and actual series. They are different from sklearn metrics in that they accept series with indices rather than np.arrays. Forecasting metrics can be invoked in two ways:
using the lean function interface, e.g.,
mean_absolute_percentage_errorwhich is a python function(y_true : pd.Series, y_pred : pd.Series) -> floatusing the composable class interface, e.g.,
MeanAbsolutePercentageError, which is a python class, callable with the same signature
Casual users may opt to use the function interface. The class interface supports advanced use cases, such as parameter modification, custom metric composition, tuning over metric parameters (not covered in this tutorial)
[ ]:
from sktime.performance_metrics.forecasting import mean_absolute_percentage_error
[ ]:
# option 1: using the lean function interface
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
# note: the FIRST argument is the ground truth, the SECOND argument are the forecasts
# the order matters for most metrics in general
To properly interpret numbers like this, it is useful to understand properties of the metric in question (e.g., lower is better), and to compare against suitable baselines and contender algorithms (see step 5).
[ ]:
from sktime.performance_metrics.forecasting import MeanAbsolutePercentageError
[ ]:
# option 2: using the composable class interface
mape = MeanAbsolutePercentageError(symmetric=False)
# the class interface allows to easily construct variants of the MAPE
# e.g., the non-symmetric verion
# it also allows for inspection of metric properties
# e.g., are higher values better (answer: no)?
mape.greater_is_better
[ ]:
# evaluation works exactly like in option 2, but with the instantiated object
mape(y_test, y_pred)
NOTE: some metrics, such as mean_absolute_scaled_error, also require the training set for evaluation. In this case, the training set should be passed as a y_train argument. Refer to the API reference on individual metrics.
NOTE: the workflow is the same for forecasters that make use of exogeneous data – no X is passed to the metrics.
step 5 – testing performance against benchmarks#
In general, forecast performances should be quantitatively tested against benchmark performances.
Currently (sktime v0.9x), this is a roadmap development item. Contributions are very welcome.
1.3.1 the basic batch forecast evaluation workflow in a nutshell – function metric interface#
For convenience, we present the basic batch forecast evaluation workflow in one cell. This cell is using the lean function metric interface.
[ ]:
from sktime.datasets import load_airline
from sktime.forecasting.base import ForecastingHorizon
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.forecasting.naive import NaiveForecaster
from sktime.performance_metrics.forecasting import mean_absolute_percentage_error
[ ]:
# step 1: splitting historical data
y = load_airline()
y_train, y_test = temporal_train_test_split(y, test_size=36)
# step 2: running the basic forecasting workflow
fh = ForecastingHorizon(y_test.index, is_relative=False)
forecaster = NaiveForecaster(strategy="last", sp=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
# step 3: specifying the evaluation metric and
# step 4: computing the forecast performance
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
# step 5: testing forecast performance against baseline
# under development
1.3.2 the basic batch forecast evaluation workflow in a nutshell – metric class interface#
For convenience, we present the basic batch forecast evaluation workflow in one cell. This cell is using the advanced class specification interface for metrics.
[ ]:
from sktime.datasets import load_airline
from sktime.forecasting.base import ForecastingHorizon
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.forecasting.naive import NaiveForecaster
from sktime.performance_metrics.forecasting import MeanAbsolutePercentageError
[ ]:
# step 1: splitting historical data
y = load_airline()
y_train, y_test = temporal_train_test_split(y, test_size=36)
# step 2: running the basic forecasting workflow
fh = ForecastingHorizon(y_test.index, is_relative=False)
forecaster = NaiveForecaster(strategy="last", sp=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
# step 3: specifying the evaluation metric
mape = MeanAbsolutePercentageError(symmetric=False)
# if function interface is used, just use the function directly in step 4
# step 4: computing the forecast performance
mape(y_test, y_pred)
# step 5: testing forecast performance against baseline
# under development
A common use case requires the forecaster to regularly update with new data and make forecasts on a rolling basis. This is especially useful if the same kind of forecast has to be made at regular time points, e.g., daily or weekly. sktime forecasters support this type of deployment workflow via the update and update_predict methods.
The update method can be called when a forecaster is already fitted, to ingest new data and make updated forecasts – this is referred to as an “update step”.
After the update, the forecaster’s internal “now” state (the cutoff) is set to the latest time stamp seen in the update batch (assumed to be later than previously seen data).
The general pattern is as follows:
specify a forecasting strategy
specify a relative forecasting horizon
fit the forecaster to an initial batch of data using
fitmake forecasts for the relative forecasting horizon, using
predictobtain new data; use
updateto ingest new datamake forecasts using
predictfor the updated datarepeat 5 and 6 as often as required
Example: suppose that, in the airline example, we want to make forecasts a year ahead, but every month, starting December 1957. The first few months, forecasts would be made as follows:
[ ]:
from sktime.datasets import load_airline
from sktime.forecasting.ets import AutoETS
from sktime.utils.plotting import plot_series
[ ]:
# we prepare the full data set for convenience
# note that in the scenario we will "know" only part of this at certain time points
y = load_airline()
[ ]:
# December 1957
# this is the data known in December 1957
y_1957Dec = y[:-36]
# step 1: specifying the forecasting strategy
forecaster = AutoETS(auto=True, sp=12, n_jobs=-1)
# step 2: specifying the forecasting horizon: one year ahead, all months
fh = np.arange(1, 13)
# step 3: this is the first time we use the model, so we fit it
forecaster.fit(y_1957Dec)
# step 4: obtaining the first batch of forecasts for Jan 1958 - Dec 1958
y_pred_1957Dec = forecaster.predict(fh)
[ ]:
# plotting predictions and past data
plot_series(y_1957Dec, y_pred_1957Dec, labels=["y_1957Dec", "y_pred_1957Dec"])
[ ]:
# January 1958
# new data is observed:
y_1958Jan = y[[-36]]
# step 5: we update the forecaster with the new data
forecaster.update(y_1958Jan)
# step 6: making forecasts with the updated data
y_pred_1958Jan = forecaster.predict(fh)
[ ]:
# note that the fh is relative, so forecasts are automatically for 1 month later
# i.e., from Feb 1958 to Jan 1959
y_pred_1958Jan
[ ]:
# plotting predictions and past data
plot_series(
y[:-35],
y_pred_1957Dec,
y_pred_1958Jan,
labels=["y_1957Dec", "y_pred_1957Dec", "y_pred_1958Jan"],
)
[ ]:
# February 1958
# new data is observed:
y_1958Feb = y[[-35]]
# step 5: we update the forecaster with the new data
forecaster.update(y_1958Feb)
# step 6: making forecasts with the updated data
y_pred_1958Feb = forecaster.predict(fh)
[ ]:
# plotting predictions and past data
plot_series(
y[:-35],
y_pred_1957Dec,
y_pred_1958Jan,
y_pred_1958Feb,
labels=["y_1957Dec", "y_pred_1957Dec", "y_pred_1958Jan", "y_pred_1958Feb"],
)
… and so on.
A shorthand for running first update and then predict is update_predict_single – for some algorithms, this may be more efficient than the separate calls to update and predict:
[ ]:
# March 1958
# new data is observed:
y_1958Mar = y[[-34]]
# step 5&6: update/predict in one step
forecaster.update_predict_single(y_1958Mar, fh=fh)
In the rolling deployment mode, may be useful to move the estimator’s “now” state (the cutoff) to later, for example if no new data was observed, but time has progressed; or, if computations take too long, and forecasts have to be queried.
The update interface provides an option for this, via the update_params argument of update and other update funtions.
If update_params is set to False, no model update computations are performed; only data is stored, and the internal “now” state (the cutoff) is set to the most recent date.
[ ]:
# April 1958
# new data is observed:
y_1958Apr = y[[-33]]
# step 5: perform an update without re-computing the model parameters
forecaster.update(y_1958Apr, update_params=False)
sktime can also simulate the update/predict deployment mode with a full batch of data.
This is not useful in deployment, as it requires all data to be available in advance; however, it is useful in playback, such as for simulations or model evaluation.
The update/predict playback mode can be called using update_predict and a re-sampling constructor which encodes the precise walk-forward scheme.
[ ]:
# from sktime.datasets import load_airline
# from sktime.forecasting.ets import AutoETS
# from sktime.forecasting.model_selection import ExpandingWindowSplitter
# from sktime.utils.plotting import plot_series
NOTE: commented out – this part of the interface is currently undergoing a re-work. Contributions and PR are appreciated.
[ ]:
# for playback, the full data needs to be loaded in advance
# y = load_airline()
[ ]:
# step 1: specifying the forecasting strategy
# forecaster = AutoETS(auto=True, sp=12, n_jobs=-1)
# step 2: specifying the forecasting horizon
# fh - np.arange(1, 13)
# step 3: specifying the cross-validation scheme
# cv = ExpandingWindowSplitter()
# step 4: fitting the forecaster - fh should be passed here
# forecaster.fit(y[:-36], fh=fh)
# step 5: rollback
# y_preds = forecaster.update_predict(y, cv)
To evaluate forecasters with respect to their performance in rolling forecasting, the forecaster needs to be tested in a set-up mimicking rolling forecasting, usually on past data. Note that the batch back-testing as in Section 1.3 would not be an appropriate evaluation set-up for rolling deployment, as that tests only a single forecast batch.
The advanced evaluation workflow can be carried out using the evaluate benchmarking function. evalute takes as arguments: – a forecaster to be evaluated – a scikit-learn re-sampling strategy for temporal splitting (cv below), e.g., ExpandingWindowSplitter or SlidingWindowSplitter – a strategy (string): whether the forecaster should be always be refitted or just fitted once and then updated
[ ]:
from sktime.forecasting.arima import AutoARIMA
from sktime.forecasting.model_evaluation import evaluate
from sktime.forecasting.model_selection import ExpandingWindowSplitter
[ ]:
forecaster = AutoARIMA(sp=12, suppress_warnings=True)
cv = ExpandingWindowSplitter(
step_length=12, fh=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12], initial_window=72
)
df = evaluate(forecaster=forecaster, y=y, cv=cv, strategy="refit", return_data=True)
df.iloc[:, :5]
[ ]:
# visualization of a forecaster evaluation
fig, ax = plot_series(
y,
df["y_pred"].iloc[0],
df["y_pred"].iloc[1],
df["y_pred"].iloc[2],
df["y_pred"].iloc[3],
df["y_pred"].iloc[4],
df["y_pred"].iloc[5],
markers=["o", "", "", "", "", "", ""],
labels=["y_true"] + ["y_pred (Backtest " + str(x) + ")" for x in range(6)],
)
ax.legend();
todo: performance metrics, averages, and testing – contributions to sktime and the tutorial are welcome.
2. Forecasters in sktime – main families#
sktime supports a number of commonly used forecasters, many of them interfaced from state-of-art forecasting packages. All forecasters are available under the unified sktime interface.
The main classes that are currently stably supported are:
ExponentialSmoothing,ThetaForecaster, andautoETSfromstatsmodelsARIMAandautoARIMAfrompmdarimaBATSandTBATSfromtbatsPolynomialTrendfor forecasting polynomial trendsProphetwhich interfaces Facebookprophet
For illustration, all estimators below will be presented on the basic forecasting workflow – though they also support the advanced forecasting and evaluation workflows under the unified sktime interface (see Section 1).
For use in the other workflows, simply replace the “forecaster specification block” (“forecaster=”) by the forecaster specification block in the examples presented below.
Generally, all forecasters available in sktime can be listed with the all_estimators command:
[ ]:
from sktime.registry import all_estimators
[ ]:
import pandas as pd
[ ]:
# all_estimators returns list of pairs - data frame conversion for pretty printing
all_estimators("forecaster", as_dataframe=True)
All forecasters follow the same interface, and can be used in the workflows presented in Section 1.
We proceed by showcasing some commonnly used classes of forecasters.
[ ]:
# imports necessary for this chapter
from sktime.datasets import load_airline
from sktime.forecasting.base import ForecastingHorizon
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.performance_metrics.forecasting import mean_absolute_percentage_error
from sktime.utils.plotting import plot_series
# data loading for illustration (see section 1 for explanation)
y = load_airline()
y_train, y_test = temporal_train_test_split(y, test_size=36)
fh = ForecastingHorizon(y_test.index, is_relative=False)
sktime interfaces a number of statistical forecasting algorithms from statsmodels: exponential smoothing, theta, and auto-ETS.
For example, to use exponential smoothing with an additive trend component and multiplicative seasonality on the airline data set, we can write the following. Note that since this is monthly data, a good choic for seasonal periodicity (sp) is 12 (= hypothesized periodicity of a year).
[ ]:
from sktime.forecasting.exp_smoothing import ExponentialSmoothing
[ ]:
forecaster = ExponentialSmoothing(trend="add", seasonal="additive", sp=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
The exponential smoothing of state space model can also be automated similar to the ets function in R. This is implemented in the AutoETS forecaster.
[ ]:
from sktime.forecasting.ets import AutoETS
[ ]:
forecaster = AutoETS(auto=True, sp=12, n_jobs=-1)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[ ]:
# todo: explain Theta; explain how to get theta-lines
sktime interfaces pmdarima for its ARIMA class models. For a classical ARIMA model with set parameters, use the ARIMA forecaster:
[ ]:
from sktime.forecasting.arima import ARIMA
[ ]:
forecaster = ARIMA(
order=(1, 1, 0), seasonal_order=(0, 1, 0, 12), suppress_warnings=True
)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
AutoARIMA is an automatically tuned ARIMA variant that obtains the optimal pdq parameters automatically:
[ ]:
from sktime.forecasting.arima import AutoARIMA
[ ]:
forecaster = AutoARIMA(sp=12, suppress_warnings=True)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[ ]:
forecaster = AutoARIMA(sp=12, suppress_warnings=True)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_pred, y_test)
[ ]:
# to obtain the fitted parameters, run
forecaster.get_fitted_params()
# should these not include pdq?
sktime interfaces BATS and TBATS from the `tbats <https://github.com/intive-DataScience/tbats>`__ package.
[ ]:
from sktime.forecasting.bats import BATS
[ ]:
forecaster = BATS(sp=12, use_trend=True, use_box_cox=False)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[ ]:
from sktime.forecasting.tbats import TBATS
[ ]:
forecaster = TBATS(sp=12, use_trend=True, use_box_cox=False)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
sktime provides an interface to `fbprophet <https://github.com/facebook/prophet>`__ by Facebook.
[ ]:
from sktime.forecasting.fbprophet import Prophet
The current interface does not support period indices, only pd.DatetimeIndex. Consider improving this by contributing the sktime.
[ ]:
# Convert index to pd.DatetimeIndex
z = y.copy()
z = z.to_timestamp(freq="M")
z_train, z_test = temporal_train_test_split(z, test_size=36)
[ ]:
forecaster = Prophet(
seasonality_mode="multiplicative",
n_changepoints=int(len(y_train) / 12),
add_country_holidays={"country_name": "Germany"},
yearly_seasonality=True,
weekly_seasonality=False,
daily_seasonality=False,
)
forecaster.fit(z_train)
y_pred = forecaster.predict(fh.to_relative(cutoff=y_train.index[-1]))
y_pred.index = y_test.index
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
We can also use the `UnobservedComponents <https://www.statsmodels.org/stable/generated/statsmodels.tsa.statespace.structural.UnobservedComponents.html>`__ class from `statsmodels <https://www.statsmodels.org/stable/index.html>`__ to generate predictions using a state space model.
[ ]:
from sktime.forecasting.structural import UnobservedComponents
[ ]:
# We can model seasonality using Fourier modes as in the Prophet model.
forecaster = UnobservedComponents(
level="local linear trend", freq_seasonal=[{"period": 12, "harmonics": 10}]
)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
sktime interfaces StatsForecast for its AutoARIMA class models. AutoARIMA is an automatically tuned ARIMA variant that obtains the optimal pdq parameters automatically:
[ ]:
from sktime.forecasting.statsforecast import StatsForecastAutoARIMA
[ ]:
forecaster = StatsForecastAutoARIMA(sp=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_pred, y_test)
3. Advanced composition patterns – pipelines, reduction, autoML, and more#
sktime supports a number of advanced composition patterns to create forecasters out of simpler components:
reduction – building a forecaster from estimators of “simpler” scientific types, like
scikit-learnregressors. A common example is feature/label tabulation by rolling window, aka the “direct reduction strategy”.tuning – determining values for hyper-parameters of a forecaster in a data-driven manner. A common example is grid search on temporally rolling re-sampling of train/test splits.
pipelining – concatenating transformers with a forecaster to obtain one forecaster. A common example is detrending and deseasonalizing then forecasting, an instance of this is the common “STL forecaster”.
autoML, also known as automated model selection – using automated tuning strategies to select not only hyper-parameters but entire forecasting strategies. A common example is on-line multiplexer tuning.
For illustration, all estimators below will be presented on the basic forecasting workflow – though they also support the advanced forecasting and evaluation workflows under the unified sktime interface (see Section 1).
For use in the other workflows, simply replace the “forecaster specification block” (“forecaster=”) by the forecaster specification block in the examples presented below.
[ ]:
# imports necessary for this chapter
from sktime.datasets import load_airline
from sktime.forecasting.base import ForecastingHorizon
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.performance_metrics.forecasting import mean_absolute_percentage_error
from sktime.utils.plotting import plot_series
# data loading for illustration (see section 1 for explanation)
y = load_airline()
y_train, y_test = temporal_train_test_split(y, test_size=36)
fh = ForecastingHorizon(y_test.index, is_relative=False)
sktime provides a meta-estimator that allows the use of any scikit-learn estimator for forecasting.
modular and compatible with scikit-learn, so that we can easily apply any scikit-learn regressor to solve our forecasting problem,
parametric and tuneable, allowing us to tune hyper-parameters such as the window length or strategy to generate forecasts
adaptive, in the sense that it adapts the scikit-learn’s estimator interface to that of a forecaster, making sure that we can tune and properly evaluate our model
Example: we will define a tabulation reduction strategy to convert a k-nearest neighbors regressor (sklearn KNeighborsRegressor) into a forecaster. The composite algorithm is an object compliant with the sktime forecaster interface (picture: big robot), and contains the regressor as a parameter accessible component (picture: little robot). In fit, the composite algorithm uses a sliding window strategy to tabulate the data, and fit the regressor to the tabulated data (picture:
left half). In predict, the composite algorithm presents the regressor with the last observed window to obtain predictions (picture: right half).
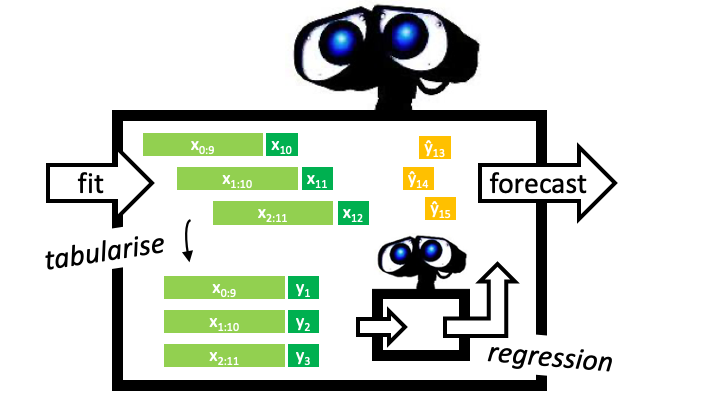
Below, the composite is constructed using the shorthand function make_reduction which produces a sktime estimator of forecaster scitype. It is called with a constructed scikit-learn regressor, regressor, and additional parameter which can be later tuned as hyper-parameters
[ ]:
from sklearn.neighbors import KNeighborsRegressor
from sktime.forecasting.compose import make_reduction
[ ]:
regressor = KNeighborsRegressor(n_neighbors=1)
forecaster = make_reduction(regressor, window_length=15, strategy="recursive")
[ ]:
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
In the above example we use the “recursive” reduction strategy. Other implemented strategies are: * “direct”, * “dirrec”, * “multioutput”.
Parameters can be inspected using scikit-learn compatible get_params functionality (and set using set_params). This provides tunable and nested access to parameters of the KNeighborsRegressor (as estimator_etc), and the window_length of the reduction strategy. Note that the strategy is not accessible, as underneath the utility function this is mapped on separate algorithm classes. For tuning over algorithms, see the “autoML” section below.
[ ]:
forecaster.get_params()
A common composition motif is pipelining: for example, first deseasonalizing or detrending the data, then forecasting the detrended/deseasonalized series. When forecasting, one needs to add the trend and seasonal component back to the data.
3.2.1 The basic forecasting pipeline#
sktime provides a generic pipeline object for this kind of composite modelling, the TransforemdTargetForecaster. It chains an arbitrary number of transformations with a forecaster. The transformations should be instances of estimators with series-to-series-transformer scitype. An example of the syntax is below:
[ ]:
from sktime.forecasting.arima import ARIMA
from sktime.forecasting.compose import TransformedTargetForecaster
from sktime.transformations.series.detrend import Deseasonalizer
[ ]:
forecaster = TransformedTargetForecaster(
[
("deseasonalize", Deseasonalizer(model="multiplicative", sp=12)),
("forecast", ARIMA()),
]
)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
The TransformedTargetForecaster is constructed with a list of steps, each a pair of name and estimator. The last estimator should be of forecaster scitype, the other estimators should be series-to-series transformers which possess both a transform and inverse_transform method. The resulting estimator is of forecaster scitype and has all interface defining methods. In fit, all transformers apply fit_transforms to the data, then the forecaster’s fit; in predict, first
the forecaster’s predict is applied, then the transformers’ inverse_transform in reverse order.
3.2.2 The Detrender as pipeline component#
For detrending, we can use the Detrender. This is an estimator of series-to-transformer scitype that wraps an arbitrary forecaster. For example, for linear detrending, we can use PolynomialTrendForecaster to fit a linear trend, and then subtract/add it using the Detrender transformer inside TransformedTargetForecaster.
To understand better what happens, we first examine the detrender separately:
[ ]:
from sktime.forecasting.trend import PolynomialTrendForecaster
from sktime.transformations.series.detrend import Detrender
[ ]:
# linear detrending
forecaster = PolynomialTrendForecaster(degree=1)
transformer = Detrender(forecaster=forecaster)
yt = transformer.fit_transform(y_train)
# internally, the Detrender uses the in-sample predictions
# of the PolynomialTrendForecaster
forecaster = PolynomialTrendForecaster(degree=1)
fh_ins = -np.arange(len(y_train)) # in-sample forecasting horizon
y_pred = forecaster.fit(y_train).predict(fh=fh_ins)
plot_series(y_train, y_pred, yt, labels=["y_train", "fitted linear trend", "residuals"]);
Since the Detrender is of scitype series-to-series-transformer, it can be used in the TransformedTargetForecaster for detrending any forecaster:
[ ]:
forecaster = TransformedTargetForecaster(
[
("deseasonalize", Deseasonalizer(model="multiplicative", sp=12)),
("detrend", Detrender(forecaster=PolynomialTrendForecaster(degree=1))),
("forecast", ARIMA()),
]
)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
3.2.3 Complex pipeline composites and parameter inspection#
sktime follows the scikit-learn philosophy of composability and nested parameter inspection. As long as an estimator has the right scitype, it can be used as part of any composition principle requiring that scitype. Above, we have already seen the example of a forecaster inside a Detrender, which is an estimator of scitype series-to-series-transformer, with one component of forecaster scitype. Similarly, in a TransformedTargetForecaster, we can use the reduction composite from
Section 3.1 as the last forecaster element in the pipeline, which inside has an estimator of tabular regressor scitype, the KNeighborsRegressor:
[ ]:
from sklearn.neighbors import KNeighborsRegressor
from sktime.forecasting.compose import make_reduction
[ ]:
forecaster = TransformedTargetForecaster(
[
("deseasonalize", Deseasonalizer(model="multiplicative", sp=12)),
("detrend", Detrender(forecaster=PolynomialTrendForecaster(degree=1))),
(
"forecast",
make_reduction(
KNeighborsRegressor(),
scitype="tabular-regressor",
window_length=15,
strategy="recursive",
),
),
]
)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
As with scikit-learn models, we can inspect and access parameters of any component via get_params and set_params:
[ ]:
forecaster.get_params()
sktime provides parameter tuning strategies as compositors of forecaster scitype, similar to scikit-learn’s GridSearchCV.
The compositor ForecastingGridSearchCV (and other tuners) are constructed with a forecaster to tune, a cross-validation constructor, a scikit-learn parameter grid, and parameters specific to the tuning strategy. Cross-validation constructors follow the scikit-learn interface for re-samplers, and can be slotted in exchangeably.
As an example, we show tuning of the window length in the reduction compositor from Section 3.1, using temporal sliding window tuning:
[ ]:
from sklearn.neighbors import KNeighborsRegressor
from sktime.forecasting.compose import make_reduction
from sktime.forecasting.model_selection import (
ForecastingGridSearchCV,
SlidingWindowSplitter,
)
[ ]:
regressor = KNeighborsRegressor()
forecaster = make_reduction(regressor, window_length=15, strategy="recursive")
param_grid = {"window_length": [7, 12, 15]}
# We fit the forecaster on an initial window which is 80% of the historical data
# then use temporal sliding window cross-validation to find the optimal hyper-parameters
cv = SlidingWindowSplitter(initial_window=int(len(y_train) * 0.8), window_length=20)
gscv = ForecastingGridSearchCV(
forecaster, strategy="refit", cv=cv, param_grid=param_grid
)
As with other composites, the resulting forecaster provides the unified interface of sktime forecasters – window splitting, tuning, etc requires no manual effort and is done behind the unified interface:
[ ]:
gscv.fit(y_train)
y_pred = gscv.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
Tuned parameters can be accessed in the best_params_ attribute:
[ ]:
gscv.best_params_
An instance of the best forecaster, with hyper-parameters set, can be retrieved by accessing the best_forecaster_ attribute:
[ ]:
gscv.best_forecaster_
As in scikit-learn, parameters of nested components can be tuned by accessing their get_params key – by default this is [estimatorname]__[parametername] if [estimatorname] is the name of the component, and [parametername] the name of a parameter within the estimator [estimatorname].
For example, below we tune the KNeighborsRegressor component’s n_neighbors, in addition to tuning window_length. The tuneable parameters can easily be queried using forecaster.get_params().
[ ]:
from sklearn.neighbors import KNeighborsRegressor
from sktime.forecasting.compose import make_reduction
from sktime.forecasting.model_selection import (
ForecastingGridSearchCV,
SlidingWindowSplitter,
)
[ ]:
param_grid = {"window_length": [7, 12, 15], "estimator__n_neighbors": np.arange(1, 10)}
regressor = KNeighborsRegressor()
forecaster = make_reduction(
regressor, scitype="tabular-regressor", strategy="recursive"
)
cv = SlidingWindowSplitter(initial_window=int(len(y_train) * 0.8), window_length=30)
gscv = ForecastingGridSearchCV(forecaster, cv=cv, param_grid=param_grid)
[ ]:
gscv.fit(y_train)
y_pred = gscv.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
[ ]:
gscv.best_params_
An alternative to the above is tuning the regressor separately, using scikit-learn’s GridSearchCV and a separate parameter grid. As this does not use the “overall” performance metric to tune the inner regressor, performance of the composite forecaster may vary.
[ ]:
from sklearn.model_selection import GridSearchCV
# tuning the 'n_estimator' hyperparameter of RandomForestRegressor from scikit-learn
regressor_param_grid = {"n_neighbors": np.arange(1, 10)}
forecaster_param_grid = {"window_length": [7, 12, 15]}
# create a tunnable regressor with GridSearchCV
regressor = GridSearchCV(KNeighborsRegressor(), param_grid=regressor_param_grid)
forecaster = make_reduction(
regressor, scitype="tabular-regressor", strategy="recursive"
)
cv = SlidingWindowSplitter(initial_window=int(len(y_train) * 0.8), window_length=30)
gscv = ForecastingGridSearchCV(forecaster, cv=cv, param_grid=forecaster_param_grid)
[ ]:
gscv.fit(y_train)
y_pred = gscv.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
NOTE: a smart implementation of this would use caching to save partial results from the inner tuning and reduce runtime substantially – currently sktime does not support this. Consider helping to improve sktime.
All tuning algorithms in sktime allow the user to set a score; for forecasting the default is mean absolute percentage error. The score can be set using the score argument, to any scorer function or class, as in Section 1.3.
Re-sampling tuners retain performances on individual forecast re-sample folds, which can be retrieved from the cv_results_ argument after the forecaster has been fit via a call to fit.
In the above example, using the mean squared error instead of the mean absolute percentage error for tuning would be done by defining the forecaster as follows:
[ ]:
from sktime.performance_metrics.forecasting import MeanSquaredError
[ ]:
mse = MeanSquaredError()
param_grid = {"window_length": [7, 12, 15]}
regressor = KNeighborsRegressor()
cv = SlidingWindowSplitter(initial_window=int(len(y_train) * 0.8), window_length=30)
gscv = ForecastingGridSearchCV(forecaster, cv=cv, param_grid=param_grid, scoring=mse)
The performances on individual folds can be accessed as follows, after fitting:
[ ]:
gscv.fit(y_train)
gscv.cv_results_
sktime provides a number of compositors for ensembling and automated model selection. In contrast to tuning, which uses data-driven strategies to find optimal hyper-parameters for a fixed forecaster, the strategies in this section combine or select on the level of estimators, using a collection of forecasters to combine or select from.
The strategies discussed in this section are: * autoML aka automated model selection * simple ensembling * prediction weighted ensembles with weight updates, and hedging strategies
The most flexible way to perform model selection over forecasters is by using the MultiplexForecaster, which exposes the choice of a forecaster from a list as a hyper-parameter that is tunable by generic hyper-parameter tuning strategies such as in Section 3.3.
In isolation, MultiplexForecaster is constructed with a named list forecasters, of forecasters. It has a single hyper-parameter, selected_forecaster, which can be set to the name of any forecaster in forecasters, and behaves exactly like the forecaster keyed in forecasters by selected_forecaster.
[ ]:
from sktime.forecasting.compose import MultiplexForecaster
from sktime.forecasting.exp_smoothing import ExponentialSmoothing
from sktime.forecasting.naive import NaiveForecaster
[ ]:
forecaster = MultiplexForecaster(
forecasters=[
("naive", NaiveForecaster(strategy="last")),
("ets", ExponentialSmoothing(trend="add", sp=12)),
],
)
[ ]:
forecaster.set_params(**{"selected_forecaster": "naive"})
# now forecaster behaves like NaiveForecaster(strategy="last")
[ ]:
forecaster.set_params(**{"selected_forecaster": "ets"})
# now forecaster behaves like ExponentialSmoothing(trend="add", sp=12))
The MultiplexForecaster is not too useful in isolation, but allows for flexible autoML when combined with a tuning wrapper. The below defines a forecaster that selects one of NaiveForecaster and ExponentialSmoothing by sliding window tuning as in Section 3.3.
Combined with rolling use of the forecaster via the update functionality (see Section 1.4), the tuned multiplexer can switch back and forth between NaiveForecaster and ExponentialSmoothing, depending on performance, as time progresses.
[ ]:
from sktime.forecasting.model_selection import (
ForecastingGridSearchCV,
SlidingWindowSplitter,
)
[ ]:
forecaster = MultiplexForecaster(
forecasters=[
("naive", NaiveForecaster(strategy="last")),
("ets", ExponentialSmoothing(trend="add", sp=12)),
]
)
cv = SlidingWindowSplitter(initial_window=int(len(y_train) * 0.5), window_length=30)
forecaster_param_grid = {"selected_forecaster": ["ets", "naive"]}
gscv = ForecastingGridSearchCV(forecaster, cv=cv, param_grid=forecaster_param_grid)
[ ]:
gscv.fit(y_train)
y_pred = gscv.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
As with any tuned forecaster, best parameters and an instance of the tuned forecaster can be retrieved using best_params_ and best_forecaster_:
[ ]:
gscv.best_params_
[ ]:
gscv.best_forecaster_
sktime also provides capabilities for automated selection of pipeline components inside a pipeline, i.e., pipeline structure. This is achieved with the OptionalPassthrough transformer.
The OptionalPassthrough transformer allows to tune whether a transformer inside a pipeline is applied to the data or not. For example, if we want to tune whether sklearn.StandardScaler is bringing an advantage to the forecast or not, we wrap it in OptionalPassthrough. Internally, OptionalPassthrough has a hyperparameter passthrough: bool that is tuneable; when False the composite behaves like the wrapped transformer, when True, it ignores the transformer within.
To make effective use of OptionalPasstrhough, define a suitable parameter set using the __ (double underscore) notation familiar from scikit-learn. This allows to access and tune attributes of nested objects like TabularToSeriesAdaptor(StandardScaler()). We can use __ multiple times if we have more than two levels of nesting.
In the following example, we take a deseasonalize/scale pipeline and tune over the four possible combinations of deseasonalizer and scaler being included in the pipeline yes/no (2 times 2 = 4); as well as over the forecaster’s and the scaler’s parameters.
Note: this could be arbitrarily combined with MultiplexForecaster, as in Section 3.4.1, to select over pipeline architecture as well as over pipeline structure.
Note: scikit-learn and sktime do not support conditional parameter sets at current (unlike, e.g., the mlr3 package). This means that the grid search will optimize over the scaler’s parameters even when it is skipped. Designing/implementing this capability would be an interesting area for contributions or research.
[ ]:
from sklearn.preprocessing import StandardScaler
from sktime.datasets import load_airline
from sktime.forecasting.compose import TransformedTargetForecaster
from sktime.forecasting.model_selection import (
ForecastingGridSearchCV,
SlidingWindowSplitter,
)
from sktime.forecasting.naive import NaiveForecaster
from sktime.transformations.series.adapt import TabularToSeriesAdaptor
from sktime.transformations.series.compose import OptionalPassthrough
from sktime.transformations.series.detrend import Deseasonalizer
[ ]:
# create pipeline
pipe = TransformedTargetForecaster(
steps=[
("deseasonalizer", OptionalPassthrough(Deseasonalizer())),
("scaler", OptionalPassthrough(TabularToSeriesAdaptor(StandardScaler()))),
("forecaster", NaiveForecaster()),
]
)
# putting it all together in a grid search
cv = SlidingWindowSplitter(
initial_window=60, window_length=24, start_with_window=True, step_length=24
)
param_grid = {
"deseasonalizer__passthrough": [True, False],
"scaler__transformer__transformer__with_mean": [True, False],
"scaler__passthrough": [True, False],
"forecaster__strategy": ["drift", "mean", "last"],
}
gscv = ForecastingGridSearchCV(forecaster=pipe, param_grid=param_grid, cv=cv, n_jobs=-1)
[ ]:
gscv.fit(y_train)
y_pred = gscv.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
TODO – contributions in this section are appreciated
[ ]:
from sktime.forecasting.compose import EnsembleForecaster
[ ]:
ses = ExponentialSmoothing(sp=12)
holt = ExponentialSmoothing(trend="add", damped_trend=False, sp=12)
damped = ExponentialSmoothing(trend="add", damped_trend=True, sp=12)
forecaster = EnsembleForecaster(
[
("ses", ses),
("holt", holt),
("damped", damped),
]
)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
For model evaluation, we sometimes want to evaluate multiple forecasts, using temporal cross-validation with a sliding window over the test data. For this purpose, we can leverage the forecasters from the online_forecasting module which use a composite forecaster, PredictionWeightedEnsemble, to keep track of the loss accumulated by each forecaster and create a prediction weighted by the predictions of the most “accurate” forecasters.
Note that the forecasting task is changed: we make 35 predictions since we need the first prediction to help update the weights, we do not predict 36 steps ahead.
[ ]:
from sktime.forecasting.all import mean_squared_error
from sktime.forecasting.online_learning import (
NormalHedgeEnsemble,
OnlineEnsembleForecaster,
)
First we need to initialize a PredictionWeightedEnsembler that will keep track of the loss accumulated by each forecaster and define which loss function we would like to use.
[ ]:
hedge_expert = NormalHedgeEnsemble(n_estimators=3, loss_func=mean_squared_error)
We can then create the forecaster by defining the individual forecasters and specifying the PredictionWeightedEnsembler we are using. Then by fitting our forecasters and performing updates and prediction with the update_predict function, we get:
[ ]:
forecaster = OnlineEnsembleForecaster(
[
("ses", ses),
("holt", holt),
("damped", damped),
],
ensemble_algorithm=hedge_expert,
)
forecaster.fit(y=y_train, fh=fh)
y_pred = forecaster.update_predict_single(y_test)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
4. Extension guide – implementing your own forecaster#
sktime is meant to be easily extensible, for direct contribution to sktime as well as for local/private extension with custom methods.
To extend sktime with a new local or contributed forecaster, a good workflow to follow is:
read through the forecasting extension template – this is a
pythonfile withtodoblocks that mark the places in which changes need to be added.optionally, if you are planning any major surgeries to the interface: look at the base class architecture – note that “ordinary” extension (e.g., new algorithm) should be easily doable without this.
copy the forecasting extension template to a local folder in your own repository (local/private extension), or to a suitable location in your clone of the
sktimeor affiliated repository (if contributed extension), insidesktime.forecasting; rename the file and update the file docstring appropriately.address the “todo” parts. Usually, this means: changing the name of the class, setting the tag values, specifying hyper-parameters, filling in
__init__,_fit,_predict, and optional methods such as_update(for details see the extension template). You can add private methods as long as they do not override the default public interface. For more details, see the extension template.to test your estimator manually: import your estimator and run it in the worfklows in Section 1; then use it in the compositors in Section 3.
to test your estimator automatically: call
sktime.tests.test_all_estimators.test_estimatoron your estimator – note that the function takes the class, not an object instance. Before the call, you need to register the new estimator insktime.tests._config, as an import, and by adding default parameter settings to theESTIMATOR_TEST_PARAMSvariable (thedictentrykeyis the class, and entry is ascikit-learnparameter set).pytestwill also add the call to its automated tests in a working clone of thesktimerepository.
In case of direct contribution to sktime or one of its affiliated packages, additionally: * add yourself as an author to the code, and to the CODEOWNERS for the new estimator file(s). * create a pull request that contains only the new estimators (and their inheritance tree, if it’s not just one class), as well as the automated tests as described above. * in the pull request, describe the estimator and optimally provide a publication or other technical reference for the strategy it
implements. * before making the pull request, ensure that you have all necessary permissions to contribute the code to a permissive license (BSD-3) open source project.
5. Summary#
sktimecomes with several forecasting algorithms (or forecasters), all of which share a common interface. The interface is fully interoperable with thescikit-learninterface, and provides dedicated interface points for forecasting in batch and rolling mode.sktimecomes with rich composition functionality that allows to build complex pipelines easily, and connect easily with other parts of the open source ecosystem, such asscikit-learnand individual algorithm libraries.sktimeis easy to extend, and comes with user friendly tools to facilitate implementing and testing your own forecasters and composition principles.
Useful resources#
For more details, take a look at our paper on forecasting with sktime in which we discuss the forecasting API in more detail and use it to replicate and extend the M4 study.
For a good introduction to forecasting, see Hyndman, Rob J., and George Athanasopoulos. Forecasting: principles and practice. OTexts, 2018.
For comparative benchmarking studies/forecasting competitions, see the M4 competition and the M5 competition.
Generated using nbsphinx. The Jupyter notebook can be found here.